

The use and monetisation of data has long been common practice in data-centric industries such as telecom and banking. As "newcomer" industries like automotive join in, it is time for a fresh approach to data monetisation, moving away from the traditional journey (see Figure 1) and elevating the concept to the next level. Companies must prepare comprehensive corporate strategies, implement organisational changes to accommodate new concepts such as "data products" and, finally, adopt proper tools to enable the full potential of data.
In this article, we will explore what the automotive industry can learn from other industries, and address its unique challenges and advantages.
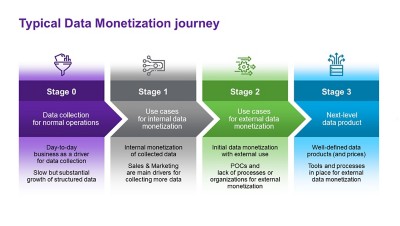
Figure 1. Typical data monetization journey
Automotive: The new (bigger) kid on the block
Though a new player in the game, the automotive industry has enormous potential to monetise data better than other sectors. McKinsey predicts that by 2030, core connectivity in-car use cases, such as gaming and over-the-air upgrades, could deliver $250 billion to $400 billion in annual incremental value for players across the mobility ecosystem.
As it enters its data monetisation journey, the automotive industry is evolving to a similar business model as other industries due to the latest innovations. The automobile — like the mobile phone — has become a connected device, with hundreds of sensors and the power to collect and analyse data. Automotive data usage used to be limited to supporting vehicle maintenance or for developing autonomous driving functionalities, but data collected once can be used many times for different purposes. There are the usual challenges around data privacy, of course, but with the proper tools and techniques it is possible to anonymise or aggregate data to ensure consumer anonymity.
Moreover, today’s cars — like phones — require frequent software updates for value-added services such as power consumption monitoring and route planning. The challenges for the automotive industry, then, are virtually identical to those faced by telecoms and financial organisations, but on an even bigger scale:
- There is more data to collect and analyse.
- There are new potential internal and external use cases for collected data.
- It is not obvious how to build boundaries to define atomic data products.
From data collection to integrated AI
How have things changed over the last few decades, before newcomers like automotive entered the picture?
Companies have been gradually collecting and using more and more data to improve decision making. Early on, the tendency was to combine data from various domains — for example, enterprise resource planning (ERP), customer relationship management (CRM) — into an enterprise data warehouse (EDW) and derive knowledge from it using business intelligence (BI) tools for reporting and dashboarding, and to train early machine learning (ML) models. The knowledge derived was then used to make decisions: what to produce, what to offer, to whom and at what price.
The approach has evolved since then, transforming the way companies collect data. Because BI tools and ML models need vast amounts of data to produce better results, companies began collecting more data than they originally needed for jobs like production control or customer service. In addition, the output from BI tools and ML models was incorporated into the core business as automated steps of customer service processes or factory maintenance processes. The process of adding more automated steps based on data and AI/ML never ends. Fast forward to today, and the age of Generative AI, which brings even more possibilities for using previously collected data and knowledge to generate yet more data.
Stage 0: Data collection for normal operations
The businesses of banks and other financial companies have for years been centered around IT systems and data. All financial institutions have their primary banking system, in which — for security and regulatory reasons — they are obliged to store and retain historical data for many years. Data is also retained for customer service purposes: Banks strive to prevent fraud or assure customers that, for example, a stolen credit card will be blocked if unusual activity is detected. To achieve this, they first need to capture, store and analyse millions of activities that the customer usually takes part in. The same goes for preventing money laundering.
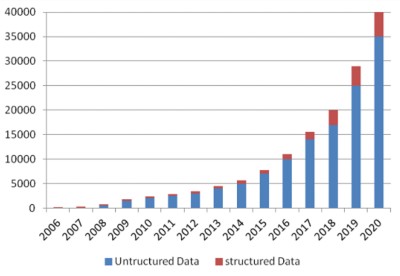
According to research conducted by The Foundation for Industrial and Technical Research (SINTEF), companies in all sectors already possessed an enormous amount of data in 2007 (single exabyte = 109 GB) (see Figure 2).
In telecoms, too, network management and billing systems had become so complicated that, without big and integrated systems, the cell phone revolution would never have happened. Users wanted better, more reliable and faster mobile connections. To achieve that, telecoms’ infrastructures needed to be monitored and analysed in real time. Over time, the same data was needed to discover new patterns or reasons for dropped connections or other service quality issues. The services used and value-added telco products had to appear on customer invoices, as well, with billing data used to construct an optimal subscription model.
Banks and telcos both operate in highly competitive industries, so market share, churn, up-sell and cross-sell are key to survival — along with efficient predictive ML models (churn, up-sell potential, next best action). But this is already the next step in our story.
Stage 1: Use cases for internal data monetisation
A shift occurred when companies started to use internal production, maintenance and service management data for different purposes, mainly for sales and marketing. Banks and telcos were early adopters, because of their instant and regular contact with customers. When credit/debit cards and mobile phones are used at least a few times a day, provider companies can collect enormous amounts of data that, after analysis, can evolve into many — sometimes surprising — business insights.
Thus a new trend was born, which, in a nutshell, can be summarised as: The more data you can collect, the better the ML models you can build, and the greater chance you have to remain relevant — or even expand — in your market. This trend, initiated about a decade ago, is still one of the key drivers for data collection, and yields important insights in business activities such as:
- Marketing:
- Up-sell/ cross-sell
- Anti-churn
- Customer segmentation and journey
- Fraud detection
- Quality of service
- Supply chain optimisation
- Cost reduction:
- Resource optimisation
- Predictive maintenance
The byproduct of this trend is a large and ever increasing data set available to companies, as well as the expansion of data warehouses, introduction of enterprise data models, a focus on data quality, management (e.g., master data management), ownership and stewardship — and, finally, big data and cloud.
Stage 2: Use cases for external data monetisation
With so much valuable data available to companies, it’s almost inevitable that the question arises: Why not sell it? Selling data is a bit like selling oil, so perhaps the better question is: Why not sell the products derived from data, i.e., the “data products”?!
The concept already exists on the market; Internet giants like Google make money on data by exposing it as a product via application programming interfaces (APIs). To reach that level of data monetisation, a few key organisational and technical components are required:
- Organisations need to adopt data product principles:
- Data ownership, even in departments that are not directly interested in data monetisation, must be specified.
- The data lifecycle needs to be controlled.
- Sales and marketing departments need to be able to understand and support the new data products business.
- Data must be constructed as a product, with all that this entails:
- The product must be precisely defined (e.g., what it is, what it is not).
- Data quality must be assured and consistently measured.
- Metadata needs to be derived, collected and maintained.
- Data product usage must be measured and be ready for billing.
- A precise billing model and billing system are required.
These steps may seem complex, but they could be introduced incrementally. You could even begin with data sub-products that customers, both internal and external, could further monetise on their own. Alternatively — and this is probably the best starting point — you could start with proofs of concept (POCs). In the auto industry, for example, that could be planning the location of a new gas station or personalising roadside digital advertisements based on customer profiles. POCs enable you to “think big, but fail fast,” to experiment without risking too much time or budget if the POC is unsuccessful.
Stage 3: Next-level data product
Once your initial data monetisation components have been implemented and proven through POCs, you can go further. Returning to the analogy of selling oil, once the raw resource is collected, it can be refined and sold as fuel for automobiles or manufactured into plastics, which are then used to create everyday household items (e.g., kitchen utensils, children’s toys). Similarly, raw data collected from customers — for example, from cars, mobile phone applications, ATMs — can be refined and developed into higher-level data products. And as with oil, the value of such products increases with complexity and accuracy.
Some examples of higher-level automotive data products include:
- Profile of place: Who is there and when?
- Profile of road: Who is using a road and when? Change in road conditions; predicted new areas of risk for drivers, pedestrians, cyclists.
- Usage pattern: How the existing functionality of a car is used (similar to an ATM in banking or mobile phone in telecoms).
- Next-best action: What the customer will do next; for example, after customers’ complaints are rejected, they are less vulnerable to advertisements or cross-sell, so it is better not to offer any new products for a while.
- Social behaviors and relations: How business partners, friends, family influence each other's choices. For example, if one member of a group buys a certain car, will others follow?
Seize the opportunity
The evolution of data monetisation demands a fresh perspective. It is imperative that organisations craft holistic corporate strategies, adapt their structures to embrace innovative concepts like data products and deploy the requisite tools to unlock the complete value of data.
For the automotive industry newcomers, the time is now to learn from the old hands in telecoms and banking and expand their idea of data monetisation. Doing it right means making the necessary organisational changes that will prepare your business for a future where data becomes an increasingly strategic product. Seize the opportunity to build a powerful, data-driven future today.
Learn more about DXC's expertise in Data & Analytics and Automotive.
About the author

Slawomir Folwarski is a partner architect in the Data Driven Development (D3) and Automotive AI Center of Excellence in the DXC Analytics practice, where he focuses on data workload optimization and analytics platforms architecture. Slawomir has 20 years of experience in the automotive, telco, public sector, logistics and finance industries, with expertise in data warehousing, business intelligence and Hadoop/Big Data technologies implemented on premises in cloud and hybrid. Since January 2023 he has been pursuing his doctorate degree in quantum computing at Capitol Technology University. Connect with Slawomir on LinkedIn.